2024-03-22 18:21:50
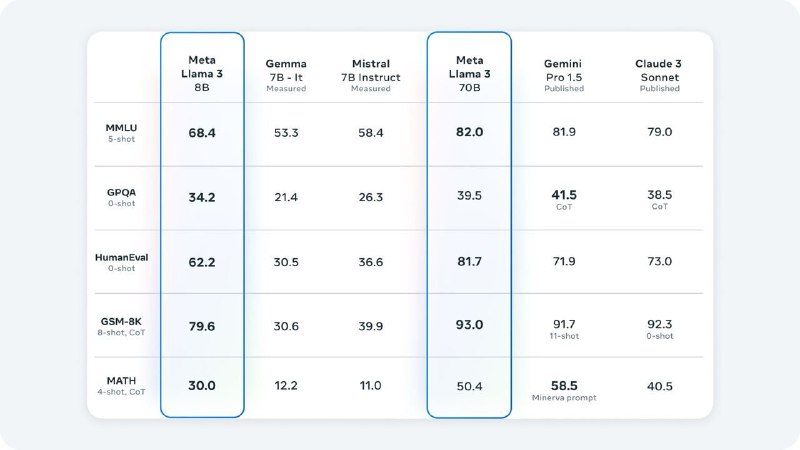
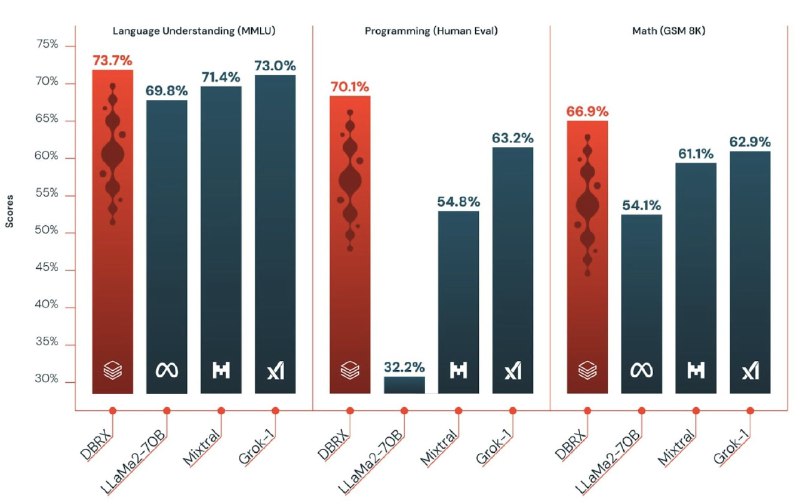
SD3-Turbo: Fast High-Resolution Image Synthesis with Latent Adversarial Diffusion DistillationВслед за Stable Diffusion 3 мои друзья опуликовали препринт о дистилляции SD3 в 4-шага, сохраняя качество.
Новый метод - Latent Adversarial Diffusion Distillation (LADD), который похож на ADD (был пост про него
), но с рядом отличий: И учитель и студент тут на архитектуре SD3 на базе трансформеров. Самая большая и самая лучшая модель - 8B параметров.
Вместо DINOv2 дискриминатора, работающего на RGB пикселях, в этой статье предлагают всеже вернуться к дискриминатору в latent space, чтобы работало быстрее и жрало меньше памяти.
В качестве дискриминатора берут копию учителя (то есть дискриминатор тренировался не дискриминативно, как в случае DINO, а генеративно). После каждого attention блока добавляют голову дискриминатора с 2D conv слоями, классифицирующую real/fake. Таким образом дискриминатор смотрит не только на финалный результат, но и на все промежуточные фичи, что усиливает тренировочный сигнал.
Тренят на картинках с разным aspect ratio, а не только на квадратах 1:1.
Убрали L2 reconstruction loss между выходами Учителя и Студента. Говорят, что тупо дискриминатора достаточно, если умно выбрать распределение семплирования шагов t.
Во время трейна более часто сеплируют t с большим шумом, чтобы студент лучше учился генерить глобальную структуру объектов.
Дистиллируют на синтетических данных, которые сгенерил учитель, а не на фото из датасета, как это было в ADD.
Еще из прикольного показали, что DPO-LoRA тюнинг хорошо так добрасывает в качество генераций студента.
Итого,
получаем SD3-Turbo модель, которая за 4 шага выдает красивые картинки. Судя по небольшому Human Eval, который авторы провели всего на 128 промптах, по image quality студент сравним с учителем. А вот prompt alignment у студента хромает, что в целом ожидаемо.
Ещё показали, что SD3-Turbo лучше чем Midjourney 6 и по качеству и по prompt alignment, что удивляет . Ждем веса, чтобы провести reality check!
Статья
@ai_newz
12.6K views15:21